[SWEA][Self Study Book Ⅰ] String: 문자열 itoa/atoi/패턴 매칭/문자 매칭 및 대표문제
❗해당 내용은 SW Expert Academy에서 제공하는 학습내용을 기반으로 하고 있습니다.
2.1. 문자열
🗨️들어가며
우리가 편지나 일기를 쓸 때, 단어들을 열거하여 문장을 쓰는 것 처럼, 컴퓨터에서도 단어들의 집합을 데이터의 형태로 사용하여 쓸 수 있다. 이것을 문자열이라고 하고, 마치 실과 같이 길게 나열되어 있어 문자열이라고 부르는 것이다.
📑문자 표현
컴퓨터에 문자를 저장하기 위한 표준화된 코드 체계에는 대표적으로 아스키코드와 유니코드가 있다. 아스키코드는 7비트, 유니코드는 16비트 체계로 유니코드가 더 업그레이드 된 버전이다. 이러한 코드 체계가 필요한 이유는 컴퓨터의 메모리가 이진 형태의 숫자만 저장 가능하기 때문이다. 기존에 아스키 코드를 미국에서 사용할 당시에는 네트워크 형성이 크지 않아 지역별로 대응되는 숫자와 문자를 정해놓고 써도 문제 없었지만 네트워크가 점점 커지고 문자도 많아지고 다국어도 생기면서 더 많은 문자를 처리할 수 있는 유니코드가 생겨났다. 그러나 유니코드를 저장할 때, 컴퓨터의 저장 형태에 따라 바이트 순서가 달라지는 경우가 있고 이 문제를 해결하기 위해 유니코드 인코딩 포맷 UTF가 등장했다.
🔖대표문제 Palindrome
“기러기” 또는 “level” 과 같이 거꾸로 읽어도 제대로 읽은 것과 같은 문장이나 낱말을 회문(palindrome)이라고 한다. 주어진 8*8 평면 글자판에서 가로,세로를 모두 보아 제시된 길이를 가진 회문의 총 개수를 구하는 문제이다.
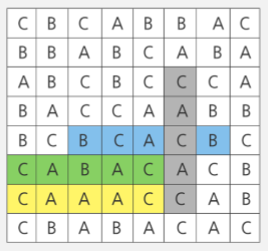
위와 같은 글자판이 주어졌을 때, 길이가 5인 회문은 색칠된 4개가 있으며 따라서 4를 리턴하면 된다.
생각해봅시다
회문인지 판단하는 함수가 핵심인 것 같다. 회문인지 판단하기 위해서는 문자열 길이의 절반까지 반복문을 돌면서 맨 앞과 끝의 문자가 같은지 비교하는 방법이 가장 직관적으로 떠오른다.
📑문자열
문자열에는 고정길이와 가변길이가 있다.
자바에서는 가변길이 문자열을 다루기 위한 string 클래스에서 기본적인 메타 데이터 뿐만 아니라, hash값, 문자열 길이, 문자열 데이터 시작점, 실제 문자열 참조 등 네 가지 필드들이 포함되어 있다. C에서의 문자열은 문자들의 배열 형태로 구현된 응용 자료형이다.
가장 뚜렷한 차이는 C는 아스키코드로 저장하고, 자바는 유니코드로 저장한다는 점이다.
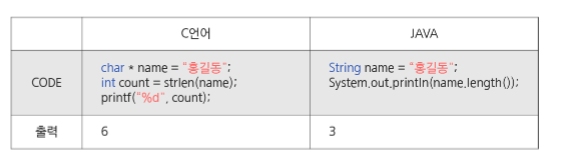
ItoA, StoI
문자열 숫자를 입력받아 정수로 리턴하는 함수
int stoi(string s){
int res = 0;
int len = s.length();
for(int i = len-1, p = 1; i >= 0; p*=10, i--){
int tmp = s[i] - 48;
res += (tmp * p);
}
return res;
}
정수를 입력받아 문자열 숫자로 리턴하는 함수
string itos(int n){
string res = "";
while(n != 0){
char tmp = (char)(n % 10) + '0';
res = tmp + res;
n /= 10;
}
return res;
}
⚙️대표문제 Palindrome
제약사항
각 칸에 들어가는 글자는 c언어 char type으로 주어지며 ‘A’, ‘B’, ‘C’ 중 하나이다. 글자 판은 무조건 정사각형으로 주어진다. ABA도 회문이며, ABBA도 회문이다. A또한 길이 1짜리 회문이다. 가로, 세로 각각에 대해서 직선으로만 판단한다. 즉, 아래 예에서 노란색 경로를 따라가면 길이 7자리 회문이 되지만 직선이 아니기 때문에 인정되지 않는다.
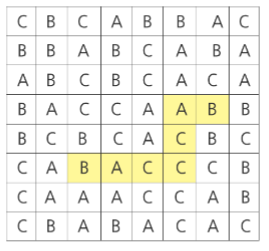
입력
첫 줄에는 테스트 케이스 개수가 주어진다. 각 테스트 케이스의 첫 번째 줄에는 찾아야 하는 회문의 길이가 주어진다. 그리고 바로 다음 줄에 테스트케이스가 주어진다.
1
4
CBBCBAAB
CCCBABCB
CAAAACAB
BACCCCAC
AABCBBAC
ACAACABC
BCCBAABC
ABBBCCAA
출력
찾은 회문의 개수를 출력한다.
12
#include<iostream>
#include<vector>
#include<algorithm>
#include<string>
#include<cstring>
using namespace std;
#define COL 8
#define ROW 8
int main(void)
{
int testcase;
int len;
cin >> testcase;
char map[COL][ROW] = { 0 };
int cnt = 0;
bool flag;
for (int t = 0; t < testcase; t++) {
cin >> len;
// map 초기화
for (int i = 0; i < COL; i++) {
for (int j = 0; j < ROW; j++) {
cin >> map[i][j];
}
}
cnt = 0; // 찾은 회문 개수를 저장할 변수를 0으로 초기화
for (int i = 0; i < ROW; i++) {
for (int j = 0; j < (ROW - len + 1); j++) {
flag = true;
for (int m = 0; m < (len / 2); m++) {
if (map[i][m + j] != map[i][j + len - m - 1]) {
flag = false;
}
}
if (flag) cnt++;
}
}
cout << cnt << endl;
}
return 0;
}
해설
2차원 배열에서 어떤 문자가 회문인지 판단하기 전에, 어떤 문자가 주어졌을 때 회문인지 판단하는 알고리즘이 중요하다.
문자열의 길이를 이용해 앞과 뒤의 문자를 하나씩 같은지 비교해보는 방법으로 판단할 수 있다.
코드 과정
- 찾은 회문 개수를 저장할 변수를 0으로 초기화
- 주어진 문자판 첫 번째 행 좌픅부터 가로 방향으로 한 문자씩 탐색을 시작한다.
- 현재 위치의 문자를 기준으로 입력받은 문자열 길이만큼의 구간에 대해 회문 여부를 판단한다. 회문인지 아닌지 저장할 변수 flag를 true로 초기화한다.
- 회문 길이가 짝수/홀수 인 것과 상관 없이 구간 양 끝 문자를 시작으로 한 칸씩 좁히며 일치하는지 검사한다
- 일치하지 않으면 flag를 false로 바꾸고 종료
- flag가 true면 회문 개수++
- 모든 행에 대해 2~3번 과정을 반복한다.
- 행에 대해 종료되면 열 방향으로 적용한다.
2.2. 문자열 패턴 매칭/문자열 매칭
🔖대표문제 패턴매칭
다음 주어진 영어 문장에서 특정한 문자열의 개수를 리턴하는 프로그램을 작성하여라.
ti를 검색하면,
Start eating well with these eight tips for healthy eating, which cover the basics of a healthy diet and good nutrition.
위 input은 답이 4가 된다.
생각해봅시다
문자열을 입력받아 찾으려는 문자열의 첫 문자가 나오면 그 뒤의 문자들을 하나씩 비교하며 찾아가는 방법이 가장 쉬울 것 같다.
📑패턴매칭
문자열에서 특정 단어나 문자열을 찾는 과정을 패턴 매칭이라고 부른다. 문자열 패턴 매칭에 사용되는 대표적인 알고리즘은 4개가 있다.
- 고지식한 패턴 검색 알고리즘
- 카프-로빈 알고리즘
- KMP 알고리즘
- 보이어-무어 알고리즘
고지식한 패턴 검색 알고리즘
바로 브루트포스 알고리즘을 말하는 것이다. 문자열을 처음부터 끝가지 차례로 순회하면서 패턴 내의 문자들을 일일이 비교하는 방식으로 동작하는 알고리즘으로, 위에서 내가 생각한 가장 쉬운 알고리즘이 바로 브루트포스, 완전탐색 알고리즘이다.
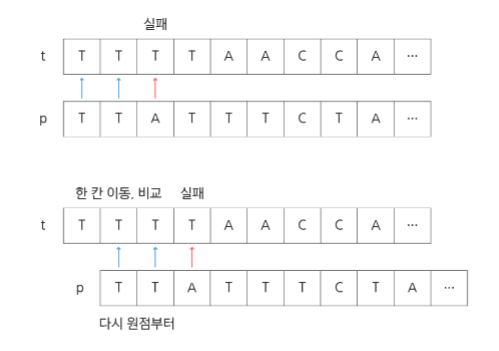
텍스트의 인덱스를 하나씩 증가시키면서 비교를 시작한다. 실패한 경우 텍스트는 원점으로 가지 않고 그 다음 인덱스부터 비교한다.
#include<iostream>
#include<vector>
#include<algorithm>
#include<string>
using namespace std;
int main(void) {
string input; string pattern;
cin >> input >> pattern;
int j;
for (int i = 0; i < input.size(); i++) {
for (j = 0; j < pattern.size(); j++) {
if (input[i + j] != pattern[j]) break;
}
if (j == pattern.size()) {
cout << "Find";
break;
}
}
return 0;
}
생각하기도 구현하기도 쉽지만 시간복잡도는 좋지만은 않다. 텍스트의 모든 위치에서 패턴을 비교해야 하므로 O(MN)이 된다.
만약 입력되는 문자열 길이가 10000이고, 패턴 길이는 80이면 최악의 경우 10000 * 80 = 800000번의 비교가 일어난다.
KMP 알고리즘
KMP 알고리즘이란, 불일치가 발생한 텍스트의 앞 부분에 어떤 문자가 있는지 미리 알고 있으므로, 불일치가 발생한 앞 부분에 대해 다시 비교하지 않고 매칭을 수행하는 알고리즘이다. 불일치가 발생한 경우 이동할 다음위치를 구해 잘못된 시작을 최소화 할 수 있다는 것이 특징이고, 시간복잡도는 O(M+N)이다.
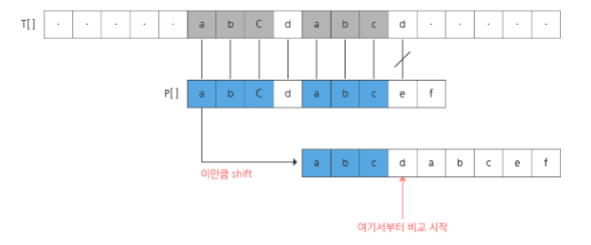
그림과 같이 매칭에 실패한 경우 배열의 첫 요소로 가지 않고, 최대한 유사한 위치에서 다시 비교한다.
이를 위해 구분을 하는 작업이 필요한데, 새로운 1차원 배열을 만들어서 해결할 수 있는데 이를 실패함수라고 한다.
실패함수는 매칭에 실패했을 때, 돌아갈 곳을 계산하는 역할을 한다.
돌아갈 곳을 계산하는 방법은 다음과 같다.
미리 패턴의 각 위치에 대해 매칭에 실패했을 때 돌아갈 곳(인덱스)을 저장한 배열을 준비해놓고, 매칭에 실패한 인덱스의 돌아갈 곳을 보고 그곳으로 돌아간다
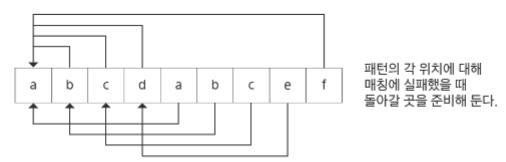
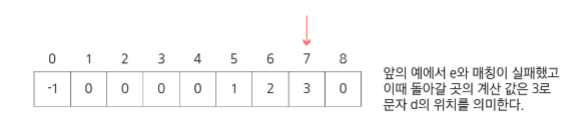
보이어-무어 알고리즘
보이어-무어 알고리즘은 패턴에 오른쪽 끝에 있는 문자가 불일치하고, 이 문자가 패턴 내에 존재하지 않는 경우, 이동거리는 패턴 길이가 된다. 대부분의 문자열 매칭 알고리즘은 왼쪽에서 시작하여 비교하지만, 이 알고리즘은 오른쪽에서 왼쪽으로 비교한다.
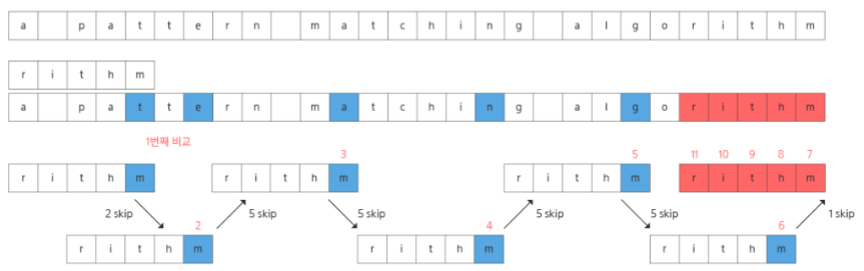
위의 사진을 통해 알고리즘을 설명해보면,
처음에 rithm과 a pat를 매칭해보게 되는데 맨 오른쪽 m과 t가 불일치하고 따라서 t가 패턴인 rithm안에 있는지 검사한다. 이 경우에는 t가 있으므로 2만큼 뛰어 t에 패턴과 문자열을 맞춰 다시 맨 오른쪽 문자를 비교한다.
m과 e가 불일치하므로 e가 rithm안에 있는지 검사하는데 없으므로 패턴 길이(5)만큼 뛰어 맨 오른쪽 문자를 또 비교한다. 앞의 과정을 반복하면서 매칭이 되는지 검사해나간다.
알고리즘 비교
| 알고리즘 | 시간복잡도 |
|---|---|
| 브루트포스 | O(mn) |
| 카프-라빈 | O(n) |
| KMP | O(n) |
| 보이어-무어 | O(n) (Worst: O(mn)) |
⚙️대표문제 패턴매칭
다음 주어진 영어 문장에서 특정한 문자열의 개수를 리턴하는 프로그램을 작성하여라.
ti를 검색하면,
Start eating well with these eight tips for healthy eating, which cover the basics of a healthy diet and good nutrition.
위 input은 답이 4가 된다.
제약사항
총 10개의 테스트케이스가 주어진다.
문장의 길이는 띄어쓰기 포함 1000자가 넘어가지 않는다.
한 문장에서 검색하는 문자열의 길이는 최대 10을 넘지 않는다.
한 문장에서는 하나의 문자열만 검색한다.
입력
첫 줄에는 테스트 케이스 개수가 주어진다. 다음 줄에는 검색 할 문자열이 주어진다. 그 다음 줄에는 문장이 주어진다.
1
ti
Start eating well with these eight tips for healthy eating, which cover the basics fo a healthy diet and good nutrition
출력
각각의 테스트케이스에 대하여 검색된 문자열의 개수를 출력한다.
4
해설
앞서 설명한 알고리즘 중 어떤 것을 사용해도 풀 수 있다. 하나 골라잡아 풀면 된다. 나는 브루트포스를 사용했다.